Patentics 搜索透镜---审查员必读
在检索过程中,经常会看到一些中国申请的公开号表有不同色度的绿色背景。这是Patentics搜索透镜发生智能“聚焦”。

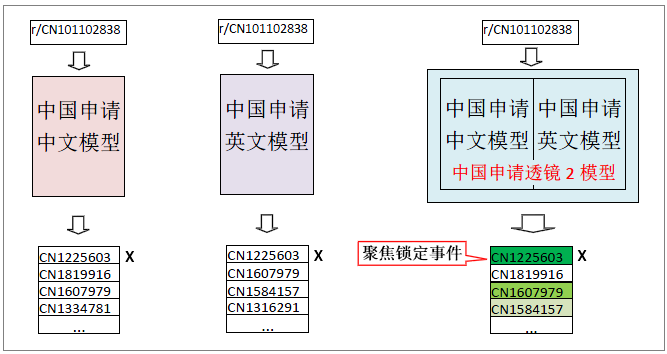

搜索透镜不仅提供了一个新的合成检索源,更为重要的是,把两个相关的检索源通过搜索透镜算法融合,构建成一个全新的智能检索决策源。通过对两个语言模型相容的排序结果的智能融合处理,我们可以计算和捕获单模型不可能出现的事件。比如说,当两个模型都将某一篇文档排序在第1位,更一般地,当两个模型都将某一篇文档排序在前i位(简称为“第i锁定”),这些锁定事件对X命中率的影响将会如何?
实际测试表明,如果某一篇文档被锁定在第1位,则该篇被锁定的文档是X文献的概率从9%跳升到20%!在单语言模型中要通过人工浏览近20篇才能达到的精度,现在只需浏览被锁定的第一篇即可达到。如果两个模型都锁定某一篇在前3位,则被锁定前3篇中为X文献的概率为34.3%,在单模型中要通过人工浏览40篇才能达到的精度,现在只需浏览最多3篇即可达到。如果两个模型都锁定某一篇在前20位,则被锁定前20篇中为X文献的概率为67.9%,在单模型中要通过人工浏览多于400篇才能达到的精度,现在只需浏览最多20篇即可达到。

必须注意,为了使Patentics搜索透镜发生作用,目前支持数据库必须选“中国申请”库。这对检索中国对比文献,不是一个限制。因为,中国申请包含中国授权。
搜索透镜不仅提供了一个新的合成检索源,更为重要的是,把两个相关的检索源通过搜索透镜算法融合,构建成一个全新的智能检索决策源。通过对两个语言模型相容的排序结果的智能融合处理,我们可以计算和捕获单模型不可能出现的事件。比如说,当两个模型都将某一篇文档排序在第1位,更一般地,当两个模型都将某一篇文档排序在前i位(简称为“第i锁定”),这些锁定事件对X命中率的影响将会如何?
实际测试表明,如果某一篇文档被锁定在第1位,则该篇被锁定的文档是X文献的概率从9%跳升到20%!在单语言模型中要通过人工浏览近20篇才能达到的精度,现在只需浏览被锁定的第一篇即可达到。如果两个模型都锁定某一篇在前3位,则被锁定前3篇中为X文献的概率为34.3%,在单模型中要通过人工浏览40篇才能达到的精度,现在只需浏览最多3篇即可达到。如果两个模型都锁定某一篇在前20位,则被锁定前20篇中为X文献的概率为67.9%,在单模型中要通过人工浏览多于400篇才能达到的精度,现在只需浏览最多20篇即可达到。
必须注意,为了使Patentics搜索透镜发生作用,目前支持数据库必须选“中国申请”库。这对检索中国对比文献,不是一个限制。因为,中国申请包含中国授权。